



Nvidia and the AI Landscape 🤖
$NVDA - Selling shovels in the rush for intelligent AI

Disclaimer: The following article contains my personal opinions and should not replace your own due diligence or be interpreted as investment advice. Please consult with a professional advisor and assess your financial situation before making any investments. I went deep with this one, but I am no technology expert. As always, do your own research.
NVDA 0.00%↑ Metrics (at time of publication)
Market Cap - $2.86T
EV = $2.90T
FCF = $46.78B
EBIT = $61.37B
Summary Ratios
P/S = 30.79
EV/EBIT = 47.25
FCF Yield = 1.63%
ROIC = 65.26
5 Year revenue CAGR = 39.06%
Introduction
Nvidia reported results for the second quarter ended on the 28th of August. Revenue increased to $30B, up 122% from the previous year, surpassing Wall Street’s expectations. This follows three straight periods of year-over-year growth in excess of 200%.
Revenue in Nvidia’s data centre segment, which includes AI processors, increased by 154% YoY, to $26.3 billion and accounted for 88% of total sales. Sales have been driven by strong demand for the Hopper GPU computing platform. Compute revenue grew more than 5x and networking revenue more than three times across the past 12 months.
Much of Nvidia's business is centred around a specific group of cloud service providers and internet companies, including Microsoft, Alphabet, Meta and Tesla. The chips, particularly the H100 and H200 models, power the vast majority of generative AI applications, such as OpenAI’s ChatGPT.
Anticipation is growing for Nvidia’s next-generation architecture, Blackwell. The company has shipped samples during the quarter and anticipate several billion dollars in Blackwell revenue in the fourth quarter.
I first wrote about NVDA 0.00%↑ back in January 2023. You can read that article here ↓.

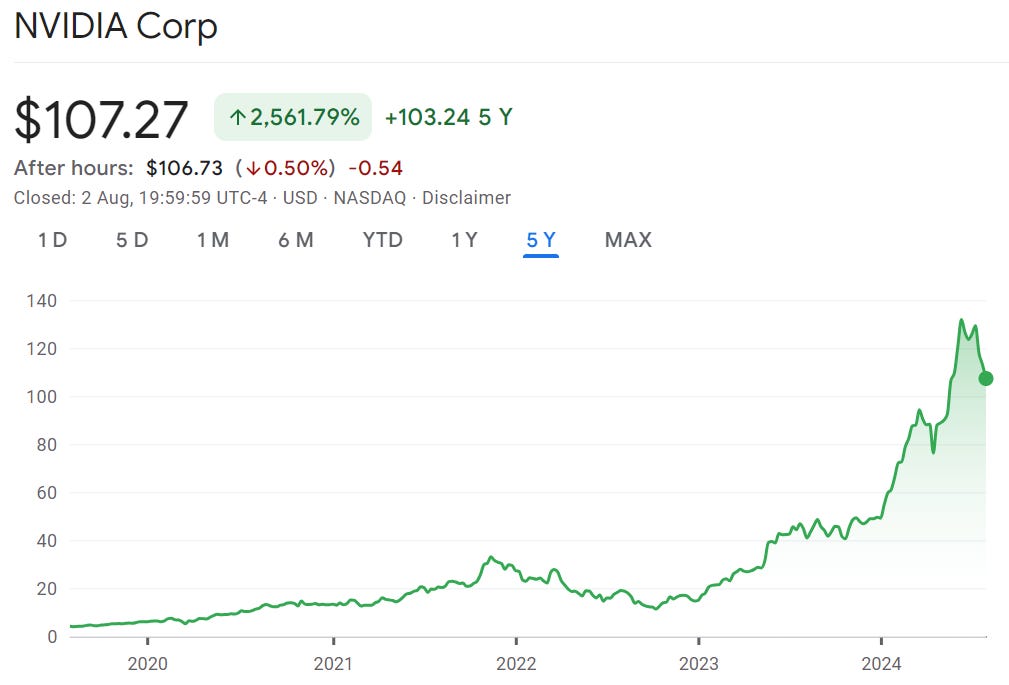
Unfortunately, I did not follow up on my research and make a share purchase 18 months ago, with the price have risen by 500%. Investors who bought during the summer of 2020 have already achieved a 10-bagger. In June 24 the market cap was over $3T and the company was briefly the most valuable in the world. CEO, Jenson Haung is almost as famous as the likes of Musk, Zuckerberg and Bezos.
So what factors have driven stratospheric growth in the share price and can the rise continue?
Background on Nvidia
Nvidia is a company that designs semiconductors - specifically GPUs (graphics processing units). GPUs are the chips housed within graphics cards. Nvidia retails GPUs for gaming, cryptocurrency mining, vehicles, robotics, professional visualisation and data centres.
The chips are manufactured by fabricators, predominantly Taiwan Semiconductor. Nvidia combines hardware with software tools, allowing developers to design software for the GPU.
Historically, Nvidia’s business has been focused on gaming. The architecture of the GPU chip means that in recent years it has been adopted for Artificial Intelligence and Deep Learning. This shift has drastically transformed the business model.
Nvidia separates the business into five segments; Data Centre, Gaming, Professional Visualisation, Automotive and OEM & Other.
Gaming was first overtaken Q2 FY23 with Data Centre becoming the largest revenue generator. The Data Centre segment has 10X’d in 5 years, with a CAGR of 58%!
")
Nvidia’s ecosystem includes hardware, software and tools that support the cycle of AI development, from training to deployment. This makes it easier for developers to work within an optimised environment, which effectively locks them in.
Nvidia has become the industry leader in providing GPU hardware for AI, meaning that research projects and commercial applications, including those at OpenAI, rely on the company’s hardware based on the reliability and performance.
The GPUs are widely used in AI R&D because they are optimised for the heavy computational workloads. Nvidia GPUs are designed for parallel processing, which is essential for training deep neural networks.
Nvidia provides specialised software frameworks, including CUDA and cuDNN that optimise the use of GPUs for AI, making development more efficient and accessible.
A reported 4 million global developers use Nvidia's CUDA software platform to build AI software and other apps. The success of the software encourages further developers to build on CUDA, creating a flywheel effect within Nvidia’s ecosystem.
CUDA had established itself as the standard for GPU software, with the majority of the deep learning programmes written on CUDA. The proprietary nature of the software has created a powerful moat and lock-in to Nvidia GPUs.
Nvidia Architecture and Chips
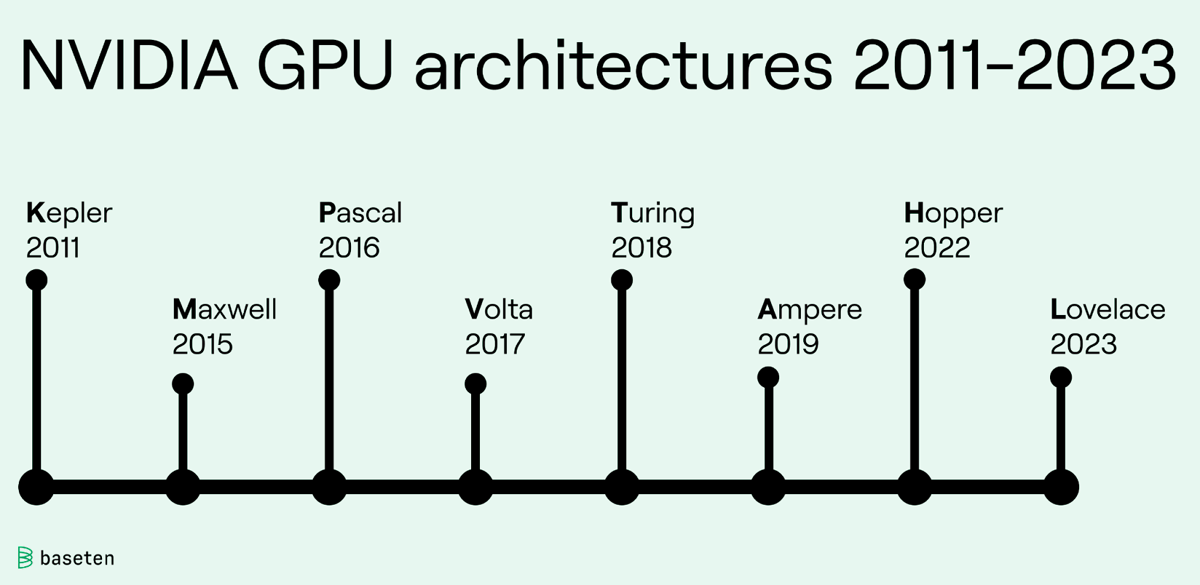
NVIDIA's architecture refers to the design and structure within the company’s GPUs. Each new generation improves the performance and efficiency of the chip. The upcoming release of Blackwell will succeed the current Hopper architecture.
The Ampere-based A100 GPU, launched in 2020 and was instrumental in advancing AI, offering high-performance computing for data centres and AI applications.
Volta, released in 2017, introduced Tensor Cores which enhanced the ability for deep learning and AI tasks. The Volta flagship GPU, the V100, became essential in data centres and high-performance computing.
In 2020, the Ampere architecture launched with the A100, doubling the efficiency and performance of Volta. The Lovelace architecture, was released in 2022, with a focus on real-time ray tracing, AI-based rendering and gaming performance.
The 2022 Hopper architecture marked a significant advancement in AI development, with the launch of the H100 GPU. The chip featured 80 billion transistors and 16,896 CUDA cores. It delivered up to six times the performance of the A100 and included the Transformer Engine alongside fourth-generation Tensor Cores, making it essential for AI and large-scale workloads.
The H100 GPU, is designed specifically for AI workloads, offering massive improvements in performance, memory bandwidth and latency over Ampere. The enhancements of the Hopper technology allowed users to remain at the cutting edge of AI. As outlined in the graph below, the H100 was reportedly 9-times faster than the A100 from training Large Language Models (LLMs).

Blackwell Architecture
Nvidia’s upcoming Blackwell architecture is expected to bring substantial improvements in computational power, efficiency and scalability. The new architecture will build on the strengths of the predecessors, enhancing the ability to tackle complex tasks while optimising energy usage and performance.
Key advancements will likely include enhanced Tensor Cores that accelerate matrix operations which are crucial for LLM training, leading to faster and more efficient model development.
Nvidia anticipates that Blackwell architecture will use 25x less energy than the Hopper chips. The B200 GPU, the flagship chip of the Blackwell architecture, is expected to deliver performance improvements over the H100, utilising 208 billion transistors, compared to H100's 80 billion.
Manufacturing problems have so far delayed the Blackwell chip release, with mass shipments may not anticipated to be undertaken until early 2025.
The B200 is rumoured to be priced between $30,000 to $40,000, which is higher than the H100's current cost of $25,000.
Let’s take a minute to assess what the current AI landscape looks like
AI Technology Landscape
According to the 2024 annual report, almost 5 million developers and 40,000 companies are reliant on Nvidia technology, with a reported 1,600 generative AI companies building on Nvidia software.
Leading LLM companies such as OpenAI, Adept, Anthropic, Character.AI, Cohere, Databricks, DeepMind, Meta, Mistral and xAI and others are building on Nvidia AI in the cloud.
Big tech companies are effectively competing to create artificial general intelligence (AGI) - a prospective digital god. The Nvidia infrastructure is arguably the most essential component of the AI revolution.
There’s a prisoner’s dilemma mentality between big tech companies. At this point, the FAANGMs of the world do not appear to be focusing on generating return on investment, instead there’s a race to build intelligent AI, where the value captured could be truly infinite.
The risk of "underinvestment" in AI is far greater than the risk of "overinvestment". The Alphabet CEO told analysts during the last earnings call. - Alphabet CEO Sundar Pichai
Alphabet reportedly plans to invest $48 billion in AI data centres in 2024. Microsoft CFO Amy Hood said on the company’s earnings call that their data centre investments are expected to support monetisation of its AI technology “over the next 15 years and beyond.”
Meta CFO Susan Li told analysts “returns from generative AI will come in over a longer period of time.”
“Gen AI is where we’re much earlier … We don’t expect our gen AI products to be a meaningful driver of revenue in ’24. But we do expect that they’re going to open up new revenue opportunities over time that will enable us to generate a solid return off of our investment.” - Meta CFO Susan Li
xAI plans a 100,000 GPU cluster, with the aim of powering Musk’s umbrella companies including SpaceX, Tesla, xAI, and X (Twitter) for their own specific AI or HPC projects. X’s Grok-2 model is set to be trained on a reported 24,000 Nvidia H100 GPUs.
Big tech companies may secretly be delighted with the prospect that the AI revolution offers. For decades these companies have been at the edge of innovation, only to find themselves stagnating in recent years, resulting in buying back shares, paying dividends, building cloud infrastructure or spending billions on the Metaverse (sorry Mark).
If the investment continues there’s a possibility the FAANGMs will pull back on returning cash to investors and even issue stock to raise cash.
The Wall Street Journal reported that Apple and Nvidia may even be future investors in OpenAI, the organisation behind Chat GPT, with Apple planning to integrate ChatGPT into iOS. Bloomberg added that Nvidia “has discussed” joining the funding round. The round is reportedly being led by Thrive Capital and would value OpenAI at more than $100 billion.
Large language model (LLMs) & Landscape
Large language model (LLMs) are AI models trained on enormous volumes of text and data in an effort to create human-like responses to effectively answer complex questions.
There are now at least five GPT-4 level models from Google, OpenAI, Anthropic, xAI and Meta.
LLM technology is based on the principles of neural network, modelled after the structure and function of the human brain. LLMs consist of interconnected nodes, or "neurons," that can process and transmit information.
ChatGPT is undoubtedly the front runner in LLM’s, generating revenue of $3.04B between January to May 2024. It has effectively become the noun for AI chatbots - similar to what Google was to search.
In the case of ChatGPT, the neural network is designed to analyse and understand language. To do this, it is trained on vast amounts of text data, including articles, books and online conversations. This data is used to "teach" the LLM to recognize patterns to make predictions about language, enabling it to provide sufficient repones to user inputs.
The likes of Google, Facebook and X have massive advantages based on the volume on information available through their databases.
Meta's Llama 3, the company’s largest LLM, was reportedly trained on a cluster of 24,000 H100 GPUs. Llama 3 powers Meta AI, an AI assistant available on Facebook, Instagram, WhatsApp and Messenger.
Tesla’s FSD Version 12, the company’s latest autonomous driving software is vision based. Video transformers consume significantly more computing power but enable better autonomous driving capabilities the automotive industry.
Nvidia hardware is now found in all Tesla vehicles. In the most recent quarter, Nvidia supported Tesla's expansion of their training AI cluster to 35,000 H100 GPUs.
Elon Musk has posted in Tweets (are they still called that?) that Grok 3 will be released by the end of the year and would require a cluster of 100,000 Nvidia H100 GPUs to be trained, meaning it would be on par with the future Chat GPT-5 model. A 100,000 GPU cluster would generate NVIDIA several billion dollars in revenue alone.
Compute Infrastructure
In the world of AI, running these large models requires more computing power, making them extremely expensive. Because of the high costs, power efficiency remains a key factor in success. Companies that can better manage their infrastructure - such as on servers and GPUs - will have a significant advantage over competition.
FLOPS (Floating Point Operations Per Second) are a measure of computational power. MFU is the percentage of this power that is being used effectively during AI model training. For example, if a company’s MFU is 35%, it means only 35% of their potential computing power is being utilised efficiently.
For many of the big AI models, such as GPT-4 or Google’s LaMDA, the MFU is between 20% and 40%. This means there is potential computing power that is not being fully utilised.
If a company can increase the MFU, it can train models faster, surpassing competitors. Higher MFU can allow for longer or more detailed training, which could lead to better-performing models. More efficient use of computing power will also reduce costs, especially when combined with techniques like quantization (which simplifies how calculations are done without significantly impacting accuracy). If a company can do this effectively, it can significantly reduce the costs of running AI models.
With multiple big tech companies creating advanced AI models, MFU is becoming a critical metric to determine which company is leading in terms of efficiency and cost-effectiveness. Higher MFU is a strong indicator of a company’s potential for success in the competitive AI landscape.
Now, back to Nvidia
Data Centre Growth
The Data Centre segment of Nvidia is providing the hardware to accelerate deep learning, machine learning and high-performance computing. Revenue has grown exponentially over the past 5 years.
Nvidia offers a suite of software tools and under the AI umbrella. This includes frameworks like Nvidia CUDA, libraries and AI models. These tools enable developers to create and deploy AI applications more efficiently.
Nvidia retails the GPUs to data centres, allowing customers to access Nvidia GPUs through cloud service providers, including Amazon Web Services (AWS), Google Cloud (GCP) and Microsoft Azure.
Nvidia’s Data Centre customers include -
Cloud Computing Data Centre - Nvidia collaborates with major cloud service providers (AWS, Azure, GCP), to enable businesses and developers to run high-compute AI, machine learning and data processing tasks without needing to own the hardware.
Supercomputing Data Centre - Offers advanced computational power to undertake tasks including quantum mechanics, weather forecasting and oil exploration.
Enterprise Data Centre - Provides servers and devices for industries such as e-commerce, web applications, financial services and healthcare.
In 2018 Data Centre was 20% of revenue, since then the segment has achieved an annual 70.55% CAGR! In the most recent quarter it made up 87% of revenue. Nvidia's data centre GPUs have become essential for processing large datasets efficiently.
Data Centre revenue more than tripled in 2024, based on higher shipments of the Hopper GPU platform.

Not only is Data Centre growth driving revenue, the segment is also delivering margin. Gross margin from the most recent quarter was 76.0%, up from 58.4% 5 years prior.
NeMo
Nvidia’s NeMo is a toolkit that simplifies the development of AI models by providing modular components, access to pretrained models and optimisations for Nvidia hardware. It enables developers to build, train and deploy AI models across a range of applications, particularly in natural language and speech processing.
NeMo is effectively a tool kit for "neural modules," which are pre-built and reusable components that can be combined to create complex AI models. These modules include layers, losses, optimisers plus the other building blocks necessary for creating deep learning models. Think photoshop for AI apps.
This modular approach allows researchers and developers to experiment by mixing and matching different modules, making it easier to customise models for specific tasks.
Users can fine-tune these models using their own data, making it easier to deploy AI models that are tailored to specific applications without needing to train from scratch.
NeMo is used for a variety of Natural Language Processing tasks, including machine translation, text summarization and question answering. It also supports speech-related tasks such as automatic speech recognition (ASR), text-to-speech (TTS) and speaker recognition. This means that NeMo can be used to build and deploy conversational AI systems, such as virtual assistants and chatbots.
A totally random fact, Lisa Su, the managing director of AMD is also Jensen Huang’s cousin.
Competition
For those companies not building on Nvidia software and infrastructure, competitors include;
AMD
AMD offers GPUs that can be used for AI and deep learning tasks. AMD has been making strides in providing alternatives, in particular the ROCm (Radeon Open Compute) platform.
At the AMD MI300 launch, the company claimed the chip had significantly better performance than Nvidia. However, AMD did not use the fastest Nvidia software. The updated results, run on Nvida software, doubled the performance claimed by AMD, with Nvidia hardware beating the MI300 by an significant 14-fold.
Nvidia’s software is optimised to improve performance on Nvidia hardware, whilst AMD has no software equivalent. AMD’s MI300X appears to be the current third fastest AI chip, behind Cerebra’s WSE CS2 and the Nvidia H100.
As of August 2024, AMD has agreed to acquire New Jersey-based ZT Systems for $4.9B in an effort to challenge Nvidia’s dominance in AI infrastructure. ZT Systems creates servers and data centre infrastructure that help in the development of AI systems. AMD hopes the acquisition will complement the silicon and software capabilities.
Google TPUs
Google produces hardware, known as TPUs (Tensor Processing Units), which are ASIC (integrated circuit chips) specifically designed for AI and machine learning tasks. GPUs and TPUs are both designed for parallel processing but with different specialisations.
TPUs are highly optimised for Google’s TensorFlow framework and are available to customers who use the Google Cloud Platform. When the TPU launched it included enough memory to store an entire model on the chip. For deep learning tasks that heavily rely on tensor operations, TPUs are often the preferred choice, while GPUs are more commonly used for applications beyond machine learning.
Regardless of the TPU acting as a competitor, Google Cloud remains a key Nvidia customer, offering GPU virtual machine powered by Nvidia. GPUs remain a core component of the Google Cloud AI Hypercomputer – Google’s supercomputing architecture.
Intel Habana Labs
Intel has invested in AI-specific hardware through its acquisition of Habana Labs, which produces the Gaudi and Goya processors for AI training and inference. These processors are designed to offer high performance and efficiency for AI workloads.
Gaudi is specifically optimised for training AI models and offers a more specialised approach compared to Nvidia’s general-purpose GPUs. Gaudi focuses on maximising performance per watt and improving cost efficiency, boasting a reported 40% speed increase over the Nvidia H100.
Custom AI Accelerators
Companies like Tesla and Apple have developed their own AI chips - such as Tesla's Dojo and Apple’s Neural Engine, used respectively autonomous driving and mobile AI.
Technology Catch Up
Nvidia reported GPU performance has increased roughly 7,000 times since 2003. Despite this, other key computing hardware and other key data centre components such as networking, storage, and memory, have to maintain a similar pace.
According to Gavin Baker, on a recent episode of ILTB, these components have only improved by 4 to 5 times in the same period, creating a technology bottleneck. This disparity leads to inefficiencies where GPUs, despite their potential, often remain underutilised. As a result, GPUs can sit idle, waiting for data to be transferred or other processes to complete, which wastes computing power and energy.
To fully harness the capabilities of GPU clusters, data centres require substantial improvements in networking, storage and memory technologies. Without these advancements, the efficiency of GPU usage can only go so far.
Conclusion
Nvidia is at the forefront of providing the infrastructure for AI, the company is building the shovels during a goldrush. There’s no doubt that AI has scope to change the world - through AGI or something less advanced is yet to be seen. As long as there is in arms race from the big tech companies - the best funded companies in history - Nvidia stands to benefit.
Big tech is unlikely to stop investing in AI even if AGI proves elusive. AI has already demonstrated value across various industries including automation, data analysis, customer experiences and optimised supply chains.
These applications are transforming business models, increasing efficiency and creating new revenue streams. Investment will continue to flow into AI to enhance existing technologies, maintain competitive advantages and explore new possibilities.
Outside of Big Tech, Pharma companies are using AI to pursue of drug discovery, whilst Hedge funds and financial institutions are developing trading algorithms. Waymo, Tesla and Cruise are investing billions to develop autonomous driving technologies.
Soon, only the big tech companies will be able to invest in advanced LLMs, barring any dramatic shift in technology. The cost of training the ChatGPT-5 model could range from $1.7 to $2.5 billion, according to HSBC. If scaling laws continue, Chat GPT-7 or 8 could cost $500 billion to train - all of which stands to benefit Nvidia.

With all this advancement in technology, investors remains overwhelmingly bullish on Nvidia stock, with the narrative focused long-term potential in AI.
Nvidia’s competitors don’t appear to pose any immediate threat.
“In the long run, we expect tech titans to strive to find second sources or in-house solutions to diversify away from Nvidia in AI, but most likely, these efforts will chip away at, but not supplant, Nvidia’s AI dominance.” - Morningstar's Brian Colello
However, threats remain on the horizon. It was reported in early September that the US Justice Department sent subpoenas to Nvidia, seeking evidence that the company had violated antitrust laws. Officials were concerned that Nvidia makes it harder to switch to other suppliers and penalises buyers that don’t exclusively use the GPU technology.
Pandora’s Box is open, but that’s not to say much stricter governing laws cannot come into place. Regulations around AI, particularly in the pursuit of AGI, may be implemented to account for concerns about the ethical, societal and security implications.
While specific regulations are still in development, it is clear that some level of oversight will be required to ensure the responsible development of advanced AI. These regulations may involve restrictions on certain applications and agreements to manage the risks associated with a race toward AGI.
The demand for Nvidia GPUs has surged with the growth of AI and machine learning, particularly with the increasing use of LLMs. This demand appears likely to continue, potentially outpacing supply, especially if constraints in the supply chain, such as at TSMC, occur.
TSMC remains a critical partner for producing Nvidia’s cutting-edge GPUs. In the short to medium term the technology may be constrained by the hardware. The A100 uses 7nm chips whilst the more advanced Nvidia H100 uses 4nm process nodes. The availability of cutting-edge hardware could be a future limiting factor.
The question for investors that remains of how large the opportunity is? Nvidia CEO Jensen Huang predicts data centre spend will double to $2 trillion in the next 5 years. He said that the rise of AI would cause data centre spending to rocket. “We’re at the beginning of this new era."
Despite the stock price and marketplace feeling ‘bubbly’ there appears to be genuine requirement and future for AI - this is not Crypto 2.0. The ongoing rise will be defined by how much value accrues to the major cloud and tech players from AI.
In pursuit of this return, big tech will continue to invest and in turn drive up Nvidia’s revenue. The two major questions that remain unanswered are 1. How long will those investments generate technological advancement (there are other limiting factors outside of the GPUs) and 2. How long can Nvidia remain as the undisputed market leader?
Nvidia’s ability to sustain the level of growth over the past several quarters is tied to the future of AI and to what extent it can be monetised.
Related articles worth reading

Sources and Further Reading
https://www.joincolossus.com/episodes/67636422/baker-ai-semiconductors-and-the-robotic-frontier?tab=transcript
https://s201.q4cdn.com/141608511/files/doc_financials/2024/ar/NVIDIA-2024-Annual-Report.pdf
https://www.tomshardware.com/tech-industry/artificial-intelligence/nvidia-ceo-hand-delivers-worlds-fastest-ai-system-to-openai-again-first-dgx-h200-given-to-sam-altman-and-greg-brockman
https://www.vox.com/business-and-finance/357250/nvidia-stock-shareholder-ai-investor-market-capitalization-bubble
https://www.datacenterdynamics.com/en/news/nvidia-ceo-jensen-huang-predicts-data-center-spend-will-double-to-2-trillion/#:~:text=Nvidia%20CEO%20Jensen%20Huang%20believes,be%20built%20across%20the%20world.
https://edition.cnn.com/2024/08/02/tech/wall-street-asks-big-tech-will-ai-ever-make-money/index.html#:~:text=Microsoft%20CFO%20Amy%20Hood%20said,CFO%20Susan%20Li%20told%20analysts.
https://www.forbes.com/sites/karlfreund/2023/12/13/breaking-amd-is-not-the-fastest-gpu-heres-the-real-data/
https://blog.paperspace.com/a100-v-h100/#:~:text=The%20first%20product%20based%20on,latency%20between%20two%20H100%20connections.
https://training.continuumlabs.ai/infrastructure/servers-and-chips/hopper-versus-blackwell
https://www.mckinsey.com/~/media/McKinsey/Industries/Semiconductors/Our%20Insights/Artificial%20intelligence%20hardware%20New%20opportunities%20for%20semiconductor%20companies/Artificial-intelligence-hardware.ashx